Google BERT, Google DeepRank là khái niệm có mối quan hệ mật thiết với nhau và có tác động rất không nhỏ đối với việc tối ưu SEO.
Được biết đến là một trong những nghiên cứu đột phá của Google trong việc xử lý ngôn ngữ tự nhiên. Google BERT và Google DeepRank đã tác động không nhỏ đến các truy vấn tìm kiếm. Vậy Google BERT và Google DeepRank là gì? Và chúng có liên hệ gì với nhau? Với bài viết này, MrH sẽ mang đến cho bạn cái nhìn chi tiết nhất về hai khái niệm này.
1. BERT
1.1. BERT là gì?
BERT là tên viết tắt của “Bidirectional Encoder Representations from Transformers”. Tạm hiểu là đại diện bộ mã hóa hai chiều từ Transformer. Đây là thuật toán chuyên sâu (Deep-learning), được thiết kế để giúp máy tính hiểu được ngôn ngữ mơ hồ trong văn bản. Thông qua việc sử dụng các phần Text xung quanh cách để tạo nên ngữ cảnh.
Dữ liệu của Google BERT có thể được tạo trước bằng việc sử dụng các nội dung từ Wikipedia. Và cũng có thể được tinh chỉnh với bộ dữ liệu câu hỏi và câu trả lời. Từ đó giúp công cụ tìm kiếm có thể hiểu chính xác ý nghĩa và sắc thái ngữ cảnh của từ (hoặc câu).
Nếu trước kia, các thuật toán về ngôn ngữ chỉ có thể đọc văn bản tuần tự theo một chiều xác định. Tuy nhiên, kể từ khi Google BERT ra đời, nó có thể đọc hiểu ngôn ngữ cùng lúc cả hai chiều. Từ trái sang phải và từ phải sang trái. Sự khác biệt này có được là nhờ sự ra đời của Transformer, hay còn được gọi là tính hai chiều.
Với tính hai chiều, Google BERT được đào tạo về hai nhiệm vụ NLP khác nhau nhưng có liên quan mật thiết với nhau. Đó là Masked Language Modeling (MLM) và Next Sentence Prediction (NSP). Mục đích của đào tạo MLM là ẩn một từ trong câu và để thuật toán dự đoán xem từ nào đã được ẩn dựa trên ngữ cảnh. Còn mục đích của đào tạo NSP nhằm dự đoán hai câu đã cho có kết nối Logic với nhau không, tuần tự không hay chỉ là ngẫu nhiên.
1.2. Giải thích BERT?
Trước khi tìm hiểu chi tiết hơn về Google BERT và các hoạt động của nó. Hãy cùng MrH xem ý nghĩ của những từ viết tắt của BERT nhé!
1.2.1. B – Bi-directional
Trước đây, các thuật toán về ngôn ngữ chỉ có thể đọc văn bản theo một chiều nhất định. Vì vậy nên chúng cũng chỉ đọc hiểu ngữ cảnh theo một hướng xác định. Điều này có thể dẫn đến một số trường hợp công cụ tìm kiếm không thể đọc hiểu một cách chính xác ngữ nghĩa của câu (từ) mà người dùng cung cấp.
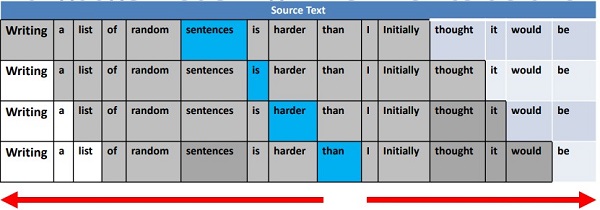
Hầu hết các trình mô hình hóa ngôn ngữ đều là đơn hướng. Nhưng Google BERT thì khác. BERT sử dụng mô hình ngôn ngữ hai chiều nên có thể đọc hiểu câu ở cả hai phía của mô hình ngôn ngữ dựa trên ngữ cảnh của từ trong cùng một lúc.
1.2.2. ER – Encoder Representation
Với cơ chế thông minh, Google BERT có thể đọc được những phần văn bản mã hóa và giải mã chúng.
1.2.3. T – Transformers
Google BERT sử dụng Transformers và mô hình ngôn ngữ bị ẩn đi. Một trong những vấn đề rất lớn đối với việc đọc hiểu ngôn ngữ tự nhiên trước đây chính là rất khó để hiểu một từ đang đề cập đến trong ngữ cảnh nào. Ví dụ, khi người dùng sử dụng các đại từ như nó, chúng nó, anh ấy, cô ấy… chẳng hạn. Công cụ tìm kiếm khó có thể theo dõi và nắm bắt một cách dễ dàng. Và Transformers sẽ thực sự tập trung vào các đại từ và tất cả ngữ nghĩa của những từ đi cùng với nó. Từ đó, cố gắng ràng buộc những đối tượng đang được nói đến trong bất kỳ ngữ cảnh nhất định.
Với mô hình ngôn ngữ bị ẩn đi (Masked Language Model – MLM), dữ liệu Input sẽ được ẩn đi (tức thay bằng một Token MASK) một cách ngẫu nhiên với tỷ lệ thấp. Mô hình này sẽ dự đoán từ được ẩn đi dựa trên bối cảnh xung quanh (là những từ không được ẩn), từ đó tìm ra biểu diễn của từ.
1.3. BERT hoạt động như thế nào?
Tiếp theo, chúng ta sẽ cùng tìm hiểu kỹ hơn về cách Google BERT hoạt động. Đồng thời hiểu được vì sao nó lại là một thuật toán giúp mô hình hóa ngôn ngữ hiệu quả. Ở phần trước, MrH đã giải thích về BERT và những gì nó có thể làm được. Vậy nó đã làm những điều đó như thế nào?
1.3.1. Kết cấu của BERT
Kết cấu của Google BERT được xây dựng dựa trên Transformer với 2 biến thể:
- BERT Large: 24 lớp (khối Encoder), 16 đầu chú ý và 340 triệu thông số
- BERT Base: 12 lớp (khối Encoder), 12 đầy chú ý và 110 triệu thông số
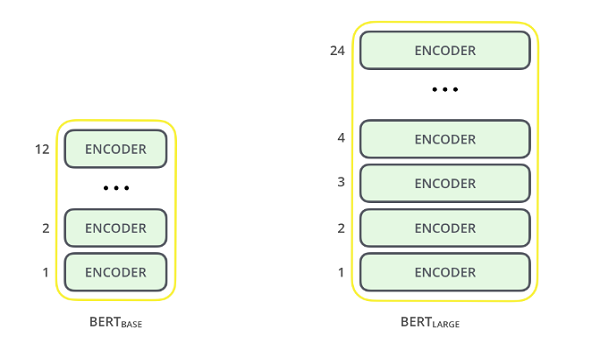
Kết cấu của BERT khá giống với mô hình GPT của OpenAI với các lớp Transformer đều là khối Encoder.
1.3.2. Tiền xử lý văn bản
Các nhà phát triển thuật toán Google BERT đã thêm một bộ các quy tắc cụ thể để đại diện cho văn bản đầu vào. Nhiều người trong số họ đã lựa chọn thiết kế sáng tạo để giúp mô hình trở nên tốt hơn.
Đối với người mới bắt đầu, mỗi lần nhúng văn bản đầu vào sẽ là sự kết hợp của 3 lần nhúng:
- Nhúng vị trí: Thuật toán BERT học và sử dụng các phép nhúng vị trí để thể hiện vị trí của các từ trên một câu. Chúng được sử dụng để khắc phục điểm hạn chế của Transformer, không thể nắm bắt thông tin “trình tự” hoặc “thứ tự”.
- Nhúng phân đoạn: BERT có thể lấy các cặp câu làm đầu vào cho các nhiệm vụ (Câu hỏi – câu trả lời). Đây chính là lý do nó học cách nhúng duy nhất cho câu đầu tiên và câu thứ hai để phân biệt chúng.
- Nhúng mã thông báo (Token): Đây là cách nhúng cho các Token cụ thể từ thư viện WorkPiece Token.
Lưu ý, đối với một Token cụ thể, tiến trình xử lý đầu vào của nó được xây dựng bằng cách tính tổng các mã nhúng Token, phân đoạn và vị trí tương ứng.
Sự kết hợp của các bước tiền xử lý này làm cho BERT trở nên linh hoạt hơn. Điều này ngụ ý rằng, bạn không cần thực hiện bất cứ thay đổi lớn nào trong cấu trúc mô hình. Mà có thể dễ dàng đào tạo nó dựa trên nhiều loại nhiệm vụ NLP.
1.3.3. Lập trình thử nghiệm
Google BERT được đào tạo trước hai nhiệm vụ NLP:
- Masked Language Modeling (MLM)
- Next Sentence Prediction (NSP)
Chúng ta hãy cùng tìm hiểu kỹ hơn về hai loại nhiệm vụ này nhé!
1.3.3.1. Masked Language Modeling (MLM)
A. CẦN THIẾT CHO TÍNH HAI CHIỀU
Thuật toán Google BERT được thiết kế như một mô hình Deeply Bidirectional (mô hình hai chiều chuyên sâu). Tựa như một mạng lưới có thể nắm bắt thông tin theo cae hai chiều bên phải và bên trái của Token từ lớp chính đầu tiên đến lớp cuối cùng.
Trước kia, chúng ta có các mô hình ngôn ngữ được đào tạo để dự đoán từ tiếp theo trong một câu. Hoặc các mô hình ngôn ngữ được tạo dựa trên ngữ cảnh từ trái sang phải. Điều này, khiến cách mô hình thường gặp lỗi do mất thông tin.
ELMo có thể giải quyết vấn đề này bằng cách tạo hai mô hình ngôn ngữ LSTM trên các ngữ cảnh từ trái sang phải hoặc từ phải sang trái. Và kết nối chúng một cách khá cứng nhắc. Mặc dù, điều này đã được cải thiện rất nhiều dựa trên các kỹ thuật hiện có. Tuy nhiên, điều đó vẫn chưa đủ.
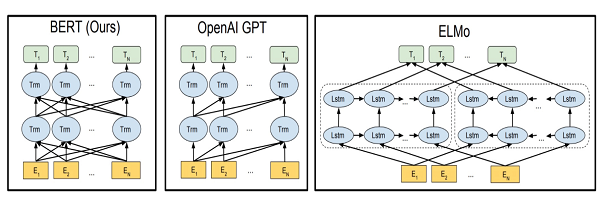
Các mũi tên trong hình trên chỉ hướng luồng thông tin di chuyển giữa các lớp. Các khối màu xanh thể hiện sự trình bày ngôn ngữ theo ngữ cảnh của mỗi từ đầu vào.
Rõ ràng, bạn có thể thấy BERT đọc hiểu ngôn ngữ theo cả hai hướng, GPT theo hướng xác định từ trái sang phải và ELMo là có xu hướng xử lý ngôn ngữ 2 chiều, nhưng không rõ ràng và cụ thể.
B. ĐÔI NÉT VỀ MASKED LANGUAGE MODELING (MLM)
Lấy một ví dụ cụ thể nhé. Xét câu “Tôi thích đọc các bài Blog cung cấp kiến thức trên MrH Asia”. Và tiến hành thiết lập mô hình ngôn ngữ hai chiều. Thay vì dự đoán các từ tiếp theo trong một chuỗi, ta có mô hình để dự đoán một từ còn thiếu trong chuỗi truy vấn.
Cụ thể bạn có thể hiểu như sau. “MrH” sẽ thay thế bằng “[MASK]”. Đay là một Token để thông báo rằng có một yếu tố bị ẩn đi. Sau đó, thuật toán sẽ tạo ra mô hình theo cách để có thể dự đoán từ “MrH” còn thiếu: “Tôi thích đọc các bài Blog cung cấp kiến thức trên [MASK] Asia”.
Điểm mấu chốt của mô hình MLM, các nhà phát triển thuật toán BERT đã đưa ra một số lưu ý để phát triển mô hình này:
- Để ngăn chặn việc tập trung quá nhiều vào một vị trí cụ thể hoặc các Token bị ẩn đi. Sẽ có ngẫu nhiên 15% số từ bị che.
- Các từ bị ẩn không phải lúc nào cũng được thay thế bằng [MASK]. Vì thông báo [MASK] sẽ không bao giờ xuất hiện trong quá trình tinh chỉnh.
- Các nhà nghiên cứu và phát triển thuật toán đã sử dụng các kỹ thuật dưới đây:
- 80% thời gian các từ được thay thế bằng Token [MASK]
- 10% thời gian các từ sẽ được thay thế bằng các từ khác một cách ngẫu nhiên
- 10% thời gian các từ sẽ được giữ nguyên vẹn
1.3.3.2. Next Sentence Prediction (NSP)
Bên cạnh mô hình MLM học cách hiệu mối quan hệ giữa các từ. Thuật toán Google BERT cũng được đào tạo về Next Sentence Prediction (NSP hay dự đoán câu tiếp theo). Với mục đích hiểu về mối quan hệ giữa các câu.
Có thể hiểu đơn giản như sau, có hai câu A và B, và mô hình NSP sẽ xác định B là câu tiếp sau A, trả lời hoặc bổ nghĩa cho A. Hay chỉ là một câu ngẫu nhiên.
Đây là một nhiệm vụ phân loại nhị phân. Vì vậy dữ liệu có thể dễ dàng được tạo ra từ bất cứ ngữ liệu nào bằng cách phân tách nó thành các cặp câu. Giả sử chúng ta đang có một tập dữ liệu văn bản 100.000 câu. Đồng nghĩa rằng sẽ có 50.000 cặp câu được tạo ra để làm dữ liệu đào tạo:
- Có 50% các cặp câu trong đó câu thứ hai thực sự là câu tiếp theo của câu đầu tiên
- Có 50% cặp câu còn lại mà trong đó câu thứ hai là một câu ngẫu nhiên
- Nhãn dán trong trường hợp đầu tiên là “IsNext” và trường hợp thứ hai là “NotNext”
Và đây là cách BERT có thể đọc hiểu ngôn ngữ một cách chính xác. Với sự kết hợp của Mô hình Masked Language Modeling (MLM) và Next Sentence Prediction (NSP).
1.4. BERT giúp giải đáp những vấn đề gì?
Công cụ tìm kiếm không thông minh đến mức có thể hiểu hết ý nghĩa của văn bản. Và các mô hình xử lý ngôn ngữ như BERT sẽ giúp giải quyết vấn đề này.
1.4.1. Vấn đề về từ ngữ
Con người sử dụng từ ngữ rất linh hoạt. Có rất nhiều từ không rõ ràng về nghĩa, đa nghĩa hoặc đồng nghĩa. Từ đồng âm, đồng nghĩa, hay từ địa phương… có thể khiến công cụ tìm kiếm hiểu sai. Ví dụ về từ đồng âm “kho”, trong câu “mẹ đem cá về kho” và “Đem cá vào cất trong kho”. “Kho” ở câu thứ nhất là động từ chỉ một hoạt động của con người. Còn ở câu thứ hai là danh từ chỉ nơi để cất giữ, chứa đồ đạc.
Việc xác định nghĩa chính xác của từ sẽ không quá khó đối với con người chúng ta. Vì chúng ta có ý thức về ngữ cảnh chung để hiểu những từ ngữ sử dụng trong tình huống nhất định. Nhưng máy móc như công cụ tìm kiếm thì không.
Sự ra đời Google BERT giúp việc đọc hiểu các câu và từ có ý nghĩa mơ hồ trở nên dễ dàng hơn, nhất là những từ (hoặc câu) có nhiều nghĩa.
1.4.2. Ngữ cảnh
Một từ sẽ không tồn tại nghĩa khi nó được sử dụng trong một ngữ cảnh cụ thể. Nghĩa của từ sẽ thay đổi khi được dùng trong những ngữ cảnh khác nhau. Giống như ví dụ được lấy ở trên. Cùng một từ “kho” nhưng khi đặt trong ngữ cảnh khác nhau sẽ có nghĩa khác nhau. Nghĩa của từ thay đổi theo nghĩa của các từ xung quanh nó. Câu càng dài, càng nhiều từ lại càng khó để hiểu nghĩa một cách chính xác. Với BERT, những vấn đề này sẽ trở nên dễ dàng hơn. Nghĩa của từ và câu được sẽ được xác định một cách chính xác nhờ mô hình xử lý ngôn ngữ thông minh dựa trên nghĩa các các từ ngữ và câu xung quanh.
1.4.3. Về NLR & NLU
Sự hiểu biết về ngôn ngữ tự nhiên cần sự linh hoạt trong việc hiểu về ngữ cảnh và suy luận. Đây là một nhiệm vụ rất dễ dàng với con người nhưng lại vô cùng khó khăn đối với máy móc, nhất là công cụ tìm kiếm.
Bên cạnh đó, ngôn ngữ tự nhiên thường không tuân theo một cấu trúc sẵn có. Những dữ liệu có cấu trúc rõ ràng sẽ dễ dàng trong việc đọc hiểu và phân biệt nghĩa của từ ngữ. Nhưng đối với dữ liệu ngôn ngữ tự nhiên với câu từ được sử dụng và sắp xếp không theo quy luật thì lại là một vấn đề không hề đơn giản chút nào nếu không có sự giúp sức của Google BERT.
Một vấn đề khác nữa, sẽ có những khoảng trống giữa các từ hoặc câu cần được lấp đầy. Bạn có thể xem một ví dụ trong hình dưới đây.

Như bạn có thể thấy, chúng ta đã xác định tất cả những thực thể và mối quan hệ giữa chúng. Lúc này, NLU sẽ tham gia vào với nhiệm vụ giúp công cụ tìm kiếm lấp đầy các khoảng trống giữa các phần đã được đặt tên.
1.5. Ảnh hưởng của BERT đối với SEO
Sự phát triển của Google BERT đã tạo ra nhiều thay đổi trong hoạt động SEO của rất nhiều doanh nghiệp. Cụ thể, sự ảnh hưởng đó được thể hiện rõ ở các điểm sau đây:
- Từ khóa đuôi dài được đề cao
- Các Website đa ngôn ngữ có ảnh hưởng tốt hơn đến từng khu vực
- Nội dung có liên quan tiếp tục được đề cao
1.5.1. Từ khóa đuôi dài được đề cao
BERT tạo điều kiện để Google có thể đọc hiểu từ ngữ một cách chính xác hơn và đặc biệt mà ngôn ngữ tự nhiên. Chính vì thế, các SEOer có thể tập trung vào các chiến lược từ khóa đuôi dài và các từ khóa mang hơi hướng ngôn ngữ tự nhiên.
Người dùng khi tiến hành tìm kiếm về một vấn đề cụ thể nào đó thường hay dùng văn nói (ngôn ngữ tự nhiên). Và nếu bạn nắm bắt được và tối ưu các từ khóa đó, chắc chắn sẽ mang lại hiệu quả SEO vô cùng lớn.
1.5.2. Các Website có nội dung đa ngôn ngữ sẽ có ảnh hưởng tốt hơn đến từng khu vực
BERT cũng mang lại những tác động tích cực cho các chiến lược SEO đa ngôn ngữ. Một trang Web được dịch sang nhiều ngôn ngữ khác nhau sẽ mang lại hiệu quả tiếp cận tốt hơn tại những khu vực, lãnh thổ quốc gia đó. Tuy nhiên, việc tạo nội dung gốc của Website bằng mỗi ngôn ngữ và cách trả lời câu hỏi của người dùng đa ngôn ngữ cần hết sức cẩn trọng.
1.5.3. Nội dung liên quan tiếp tục được đề cao
Sự ra đời của BERT đã nâng cấp khả năng đọc hiểu ngôn ngữ của công cụ tìm kiếm. Các Website giờ đây sẽ khó đạt được thứ hạng cao nếu chỉ đưa ra những nội dung đơn giản, kém chất lượng. Với sự trợ giúp của BERT, Google có thể hiểu rõ hơn ý định của người dùng đằng sau truy vấn tìm kiếm. Và các kết quả có mức độ liên quan cao nhất sẽ được trả về chứ không đơn thuần là những Website chỉ nhắm mục tiêu tối ưu từ khóa để tăng lượng truy cập. Nói cách khác, nếu muốn Website có được thứ hạng cao trên trang kết quả tìm kiếm. Ngoài việc lên kế hoạch tối ưu từ khóa, bạn cần phải tạo ra nội dung thật sự chất lượng. Và đáp ứng nhu cầu tìm kiếm của người dùng.
Chỉ nội dung hay nhất, độc đáo nhất và giải đáp chính xác thắc mắc của người dùng mới xứng đáng có được vị trí cao trên Google SERP. Và nhận về lượng truy cập cao mà không phải trả tiền.
“Content is KING” quả thật rất đúng trong trường hợp này. Khi các thuật toán về ngôn ngữ ngày một cải tiến và điển hình là sự xuất hiện Google BERT. Thì việc đầu tư cho sáng tạo nội dung để tối ưu trải nghiệm của người dùng cũng trở nên quan trọng hơn bao giờ hết.
Google BERT đã mang lại thay đổi không hề nhỏ đối với các hoạt động tối ưu SEO. Xét cho cùng, chiến lược tốt nhất doanh nghiệp cần quan tâm lúc này chính là sản xuất nội dung có giá trị và phù hợp với đối tượng mục tiêu bạn đang hướng đến. Vốn dĩ đã là phương châm vận hành của dịch vụ SEO Website của MrH.
2. Google DeepRank
Google đã tiết lộ các chi tiết mới về việc tạo ra thuật toán DeepRank – một thuật toán hiển thị các kết quả tìm kiếm phù hợp nhất bằng cách đọc hiểu ngôn ngữ tự nhiên của con người.
Vậy DeepRank chính xác là gì? Nó hoạt động như thế nào? Và nó có quan hệ gì đối với thuật toán BERT?
2.1. Google DeepRank là gì?
Được ra mắt vào năm 2019, bạn có thể hiểu đơn giản DeepRank là sự tích hợp BERT vào Google tìm kiếm. Tên gọi này xuất phát từ phương pháp Deep Learning được BERT sử dụng và khía cạnh xếp hạng tìm kiếm (Rank).
Google DeepRank được xây dựng dựa trên khả năng Machine Learning và xử lý ngôn ngữ tự nhiên hiện có của Google. Xử lý ngôn ngữ tự nhiên ở đây cho phép người dùng nhập các câu hỏi thực tế. Với ngôn ngữ giống như tin nhắn văn bản hay cuộc đối thoại thường ngày.
Trong suốt 20 năm qua. Google luôn nỗ lực để nâng cao hiệu quả trong việc xử lý ngôn ngữ tự nhiên để mang đến trải nghiệm tối ưu nhất cho người dùng. Bắt đầu từ việc sửa lỗi chính tả và hiểu các các từ đồng nghĩa. Khả năng học của Google đã phát triển mạnh mẽ trong 10 năm trở lại đây. Và sự ra đời thuật toán BERT đã nâng cao khả năng của Google trong việc đọc hiểu ngôn ngữ tự nhiên. Dù đã trải qua một chặng đường rất dài để tối ưu xếp hạng tìm kiếm. Nhưng chỉ khi ứng dụng BERT, công cụ tìm kiếm mới có cái nhìn chính xác hơn về sự tinh tế trong ngôn ngữ của con người.
Có thể nói, DeepRank là dấu mốc cho thấy những nỗ lực to lớn của Google để hiểu người dùng. Giúp công cụ tìm kiếm trở nên trực quan hơn khi sử dụng và tạo cảm giác Google như cá nhân thực sự. Có thể hiểu chính xác mong muốn của người dùng.
2.2. Google DeepRank hoạt động thế nào?
DeepRank có thể hiểu được những nét tinh tế của ngôn ngữ tự nhiên. Nhưng để làm được như vậy, việc lập trình thực sự không hề đơn giản một chút nào.
Các thuật toán tìm kiếm của Google được sử dụng để lược bỏ những từ đệm và loại bỏ chúng khỏi truy vấn. Theo thời gian, Google dần hiểu được những từ này có vai trò quan trọng trong việc truyền đạt chính xác những gì người dùng muốn nói. Với DeepRank, bạn có thể thực hiện các truy vấn một cách tự nhiên mà không gặp phải vấn đề công cụ tìm kiếm hiểu sai nghĩa.
Ví dụ, khi thực hiện truy vấn: “What temperature should you pre-heat your oven to when cooking fish?”
Nếu không có Google DeepRank, Google SERP sẽ hiển thị một số thông tin hữu ích. Nhưng có thể xảy ra sự nhầm lẫn. Khi ứng dụng Google DeepRank, công cụ tìm kiếm sẽ hiểu chính xác hơn nhu cầu tìm kiếm của người dùng. Đồng thời loại bỏ những kết quả không liên quan.
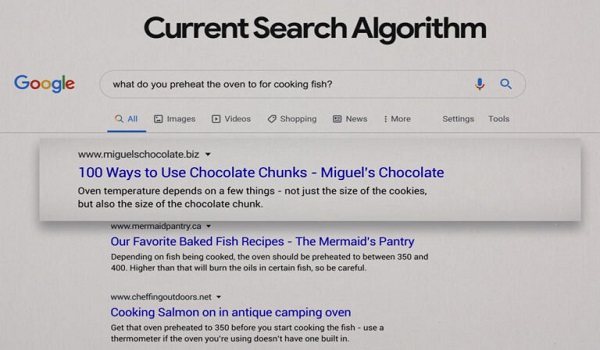
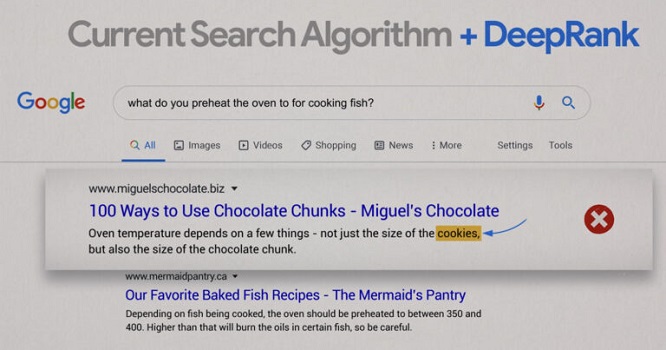
Một ví dụ khác mà bạn có thể nhìn thấy rõ hơn với truy vấn: “Can you get medicine for someone pharmacy”. Ở bên trái của hình ảnh dưới đây là kết quả hiểu và trả lời truy vấn cụ thể (nhờ Google DeepRank). Và bên phải là kết quả chung về việc mua thuốc theo toa.

Đến đây, chúng ta cũng phần nào hiểu được cách mà Google DeepRank hoạt động và cải thiện trang kết quả tìm kiếm như thế nào.
3. Mối quan hệ giữa Google BERT và Google DeepRank là gì?
Qua những phân tích trên, bạn cũng có thể thấy thực chất Google BERT và Google DeepRank hoạt động giống nhau. Vậy tại sao lại tồn tại hai khái niệm này và chúng thật sự có mối quan hệ như thế nào?
Thật ra, bạn có thể hiểu Google BERT và Google DeepRank là một. Cụ thể, như đã trình bày ở phần 1, BERT là tên gọi của một thuật toán ra đời vào năm 2017. Với mục đích đọc hiểu ngôn ngữ theo hai chiều cùng một lúc và xử lý ngôn ngữ tự nhiên một cách tốt hơn. Vào năm 2018, Google đã thông báo ứng dụng thử nghiệm thuật toán BERT. Và nghiên cứu phát triển khả năng phân tích ngôn ngữ của công cụ tìm kiếm giống với con người. Đến tháng 10/2019, Google đã chính thức thông báo áp dụng BERT cho thuật toán tìm kiếm với cái tên Google DeepRank.
4. Kết luận
Sự xuất hiện của Google BERT/Google DeepRank là bước tiến quan trọng giúp Google tối ưu xếp hạng tìm kiếm của mình. Đồng thời mang lại trải nghiệm tìm kiếm tự nhiên tốt nhất cho người dùng.
MrH hy vọng rằng những thông tin mà bài viết cung cấp sẽ giúp bạn có thêm kiến thức về Google BERT và Google DeepRank, cũng như mối quan hệ giữa chúng. Từ đó, hiểu rõ hơn về những ảnh hưởng của thuật toán này đối với SEO và tìm cách tối ưu tốt nhất. Nếu bạn vẫn còn nhắc thắc mắc về Google BERT hay các vấn đề liên quan đến quy trình SEO. Hãy liên hệ với MrH để được giải đáp và tư vấn chi tiết nhất nhé!